Chu and Choi: Noise Reduction Using Wavelet Thresholding of Multitaper Estimators and Geometric Approach to Spectral Subtraction for Speech Coding Strategy
Abstract
Objectives
Noise reduction using wavelet thresholding of multitaper estimators (WTME) and geometric approach to spectral subtraction (GASS) can improve speech quality of noisy sound for speech coding strategy. This study used Perceptual Evaluation of Speech Quality (PESQ) to assess the performance of the WTME and GASS for speech coding strategy.
Methods
This study included 25 Mandarin sentences as test materials. Environmental noises including the air-conditioner, cafeteria and multi-talker were artificially added to test materials at signal to noise ratio (SNR) of -5, 0, 5, and 10 dB. HiRes 120 vocoder WTME and GASS noise reduction process were used in this study to generate sound outputs. The sound outputs were measured by the PESQ to evaluate sound quality.
Results
Two figures and three tables were used to assess the speech quality of the sound output of the WTME and GASS.
Conclusion
There is no significant difference between the overall performance of sound quality in both methods, but the geometric approach to spectral subtraction method is slightly better than the wavelet thresholding of multitaper estimators.
Keywords: Cochlear implant; Speech production measurement
INTRODUCTION
One of the main challenges in developing an efficient cochlear implant lies in speech coding strategy that can elicit neural sensations that correspond to those generated by the normal hearing mechanism. Currently, the speech coding strategy of cochlear implants has improved significantly over the past few decades as a result of advancements in technology. In a quiet environment, some of the cochlear implant users achieved sentence intelligibility scores of 80% to 90%. However, the ability of most implant users to understand speech in noisy environments, understand music and understand tone languages remain a challenge to improve.
Even though most speech enhancement algorithms are able to improve speech quality for speech coding strategy they suffer from an annoying artifact called "musical noise" ( 1- 3). Musical noise is caused by randomly spaced spectral peaks that come and go in each frame, and occur at random frequencies. The randomly spaced peaks are due to the inaccurate and large-variance estimates of the spectra of noise and noisy signals, typically computed using periodogram-type methods ( 3). Two noise reduction methods for speech coding strategy that can reduce musical noise are discussed in this study: the wavelet thresholding of multitaper estimators (WTME) ( 3) and the geometric approach to spectral subtraction (GASS) ( 4, 5). In order to evaluate the sound quality of the discussed algorithms, the Perceptual Evaluation of Speech Quality (PESQ) ( 6, 7) objective measurement is used.
MATERIALS AND METHODS
This study included 25 sentences of test materials. The sentences were recorded in Mandarin and produced by a male speaker. The sentences were originally sampled in 44.1 kHz and down sampled to 16 kHz. Noise from different environments was artificially added to test materials, including air-conditioner, cafeteria and multi-talker, at SNRs of -5, 0, 5, and 10 dB. A total of 300 combination signals were generated (25 sentences├Ś3 noises├Ś4 difference signal to noise ratio [SNR]).
This study used a HiRes 120 strategy ( 8) together with a noise reduction process ( Fig. 1) as the speech coding strategy or vocoder. All the test materials were processed as the input sound of the vocoder and total of 600 sound outputs were generated (300 input sounds├Ś2 noise reduction methods). The sound outputs were then measured by the PESQ ( Figs. 1- 3) to evaluate the sound quality. The PESQ evaluation ( 6) begins by level aligning both signals to a standard listening level. They are filtered (using a fast Fourier transform [FFT]) with an input filter to model a standard telephone handset. The signals are aligned in time and then processed through an auditory transform similar to that of perceptual speech quality measure (PSQM). The transformation also involves equalising for linear filtering in the system and for gain variation. Two distortion parameters are extracted from the disturbance (the difference between the transforms of the signals), and are aggregated in frequency and time and mapped to a prediction of subjective mean opinion score (MOS). The final PESQ score is a linear combination of the average disturbance value and the average asymmetrical disturbance value. The range of the PESQ score is -0.5 to 4.5, although for most cases the output range will be a listening quality MOS-like score between 1.0 and 4.5, the normal range of MOS values found in an absolute category rating (ACR) experiment ( 7). The bigger the value of PESQ is, the better the sound quality will be. Two noise reduction methods were implemented in the vocoder. The first noise reduction method, WTME ( 3, 9, 10) can be implemented in four steps. For each speech frame:
Calculate the logarithm of the multitaper estimate. Apply a standard, periodic, partial discrete wavelet transform (DWT) out to decomposition level (q0) to the log periodogram ordinates and get the empirical DWT. For implementation, q0=5. Apply thresholding to the wavelet coefficients. Invert the partial DWT to the thresholded wavelet coefficients and produce the smoothed spectrum estimate.
The second noise reduction method, GASS ( 4, 5) can be implemented in five steps. For each speech frame:
Using the FFT magnitude spectrum of the noisy signal. Using a noise estimation algorithm (5), update the power spectrum of the noise signal. Compute the instantaneous estimate and use it to compute the smoothed estimate. Then estimate the gain function (4). Obtain the enhanced magnitude spectrum by the product of noisy signal and gain. Compute the inverse FFT with enhanced magnitude spectrum to obtain the enhanced speech signal.
RESULTS
The performance of the two methods in measuring speech quality is showed in Tables 1- 3 and Figs. 4, 5. Firstly, Table 1 showed the PESQ scores of 25 sentences from difference background environments (air-conditioner, cafeteria and multi-talker) at SNRs of -5, 0, 5, and 10 dB that processed by the WTME noise reduction method in the HiRes 120 vocoder. The PESQ scores of 25 sentences from difference background environments (air-conditioner, cafeteria and multi-talker) at SNRs of -5, 0, 5, and 10 dB that processed by the GASS noise reduction method in the HiRes 120 vocoder is showed in Table 2. Table 3 showed the PESQ mean scores of sentences from difference background environments (air-conditioner, cafeteria and multi-talker) at difference SNR that processed by the WTME and GASS noise reduction methods in the HiRes 120 vocoder. Fig. 4 shows the mean value of each SNR based on difference background environment whereas Fig. 5 shows the overall PESQ mean value of each SNR.
DISCUSSION
Based on the results shown in Fig. 4, the PESQ mean of each difference background environments mostly score between 1.0 to 1.6 and only few PESQ mean scores are below 1.0, which are poor in sound quality. The WTME fail to improve the sound quality when the SNR is -5 dB under air-conditioning, cafeteria and multi-talker background environments condition. The GASS shows poor sound quality when the SNR is -5 dB under the multi-talker background environment condition. Both noise reduction methods have poor sound quality in multi-talker environment when the SNR is -5 dB because the noise estimator in both methods unable to estimate the correct speech or noise activity when the noise energy is bigger than speech signal energy, in which the noise might appear to be similar to "speech" signal.
Fig. 4 shows that both noise reduction methods are able to perform better sound quality when the SNR values increase. There is no significant difference between the sound quality performances in both methods, except for WTME in the multi-talker background environment. The overall mean value of each SNR ( Fig. 5) indicated that there is no significant difference between the performances of both methods, except for WTME when SNR is -5dB.
To conclude, there is no significant difference between the overall performance of sound quality by both methods, but the GASS method is slightly better than the WTME.
CONFLICT OF INTEREST
No potential conflict of interest relevant to this article was reported.
References
1. Boll S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans Acoust. 1979 4;27(2):113-120.  2. Berouti M, Schwartz R, Makhoul J. Enhancement of speech corrupted by acoustic noise. IEEE International Conference on Acoustics, Speech and Signal Processing. 1979 Apr 2-4; Washington, DC, USA. p. 208-211. 3. Hu Y, Loizou PC. Speech enhancement based on wavelet thresholding the multitaper spectrum. IEEE Trans Speech Audio Process. 2004 1;12(1):59-67. 4. Lu Y, Loizou PC. A geometric approach to spectral subtraction. Speech Commun. 2008 1;50(6):453-466. PMID: 19122867.   5. Martin R. Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Trans Speech Audio Process. 2001 7;9(5):504-512. 6. Rix AW, Beerends JG, Hollier MP, Hekstra AP. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. IEEE International Conference on Acoustics, Speech and Signal Processing. 2001 May 7-11; Salt Lake City, UT, USA. p. 749-752. 8. Choi CT, Hsu CH, Tsai WY, Lee YH. A vocoder for a novel cochlear implant stimulating strategy based on virtual channel technology. 13th International Conference on Biomedical Engineering. 2008 Dec 3-6; Singapore. p. 310-313. 9. Riedel KS, Sidorenko A. Minimum bias multiple taper spectral estimation. IEEE Trans Signal Process. 1995 1;43(1):188-195. 10. Walden AT, Percival DB, McCoy EJ. Spectrum estimation by wavelet thresholding of multitaper estimators. IEEE Trans Signal Process. 1998 12;46(12):3153-3165.
Fig.┬Ā1
HiRes 120 vocoder with noise reduction process. 
Fig.┬Ā2
Structure of perceptual evaluation of speech quality model ( 6). 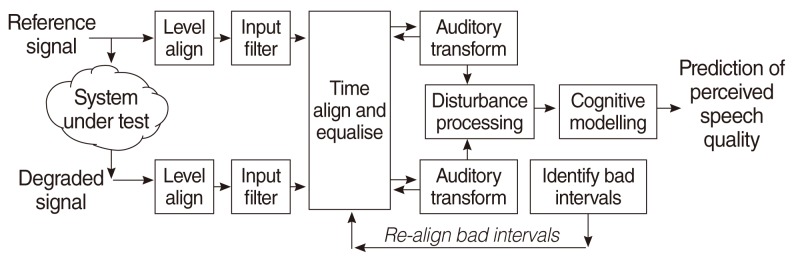
Fig.┬Ā3
Perceptual Evaluation of Speech Quality (PESQ) evaluation method for testing quality with environmental noise ( 7). 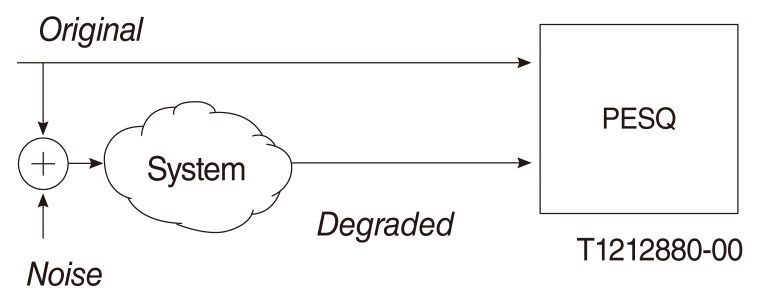
Fig.┬Ā4
The mean value of each signal to noise ratio (SNR) based on difference background environment. 
Fig.┬Ā5
The overall mean value of each signal to noise ratio (SNR). 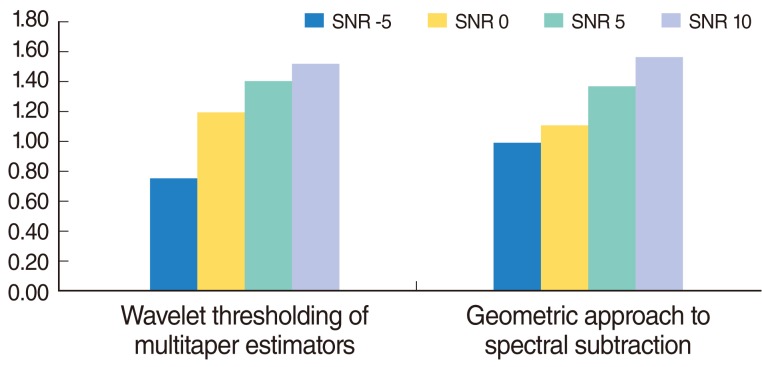
Table┬Ā1
The perceptual evaluation of speech quality scores of 25 sentences from difference background environments at signal to noise ratios (SNRs) of -5, 0, 5, and 10 dB*

Table┬Ā2
The perceptual evaluation of speech quality scores of 25 sentences from difference background environments at signal to noise ratios (SNRs) of -5, 0, 5, and 10 dB*
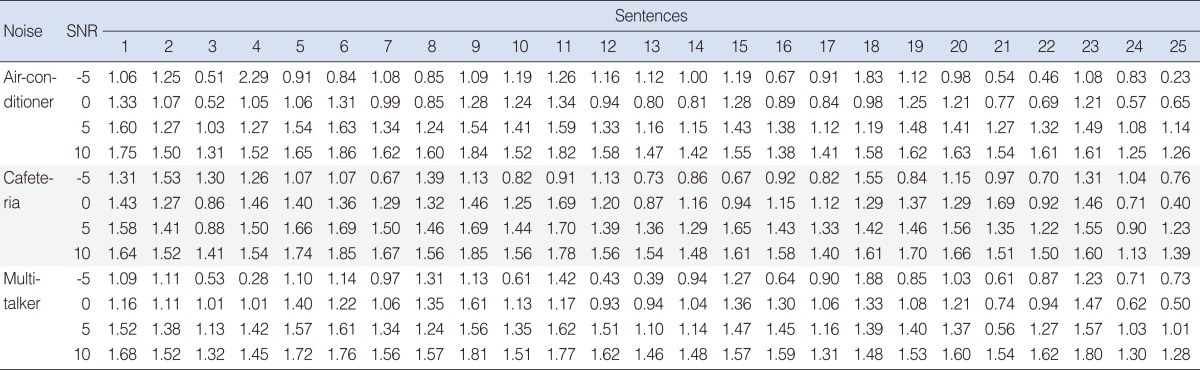
Table┬Ā3
The perceptual evaluation of speech quality mean scores of sentences from difference background environments at difference signal to noise ratio (SNR)*

|
|








